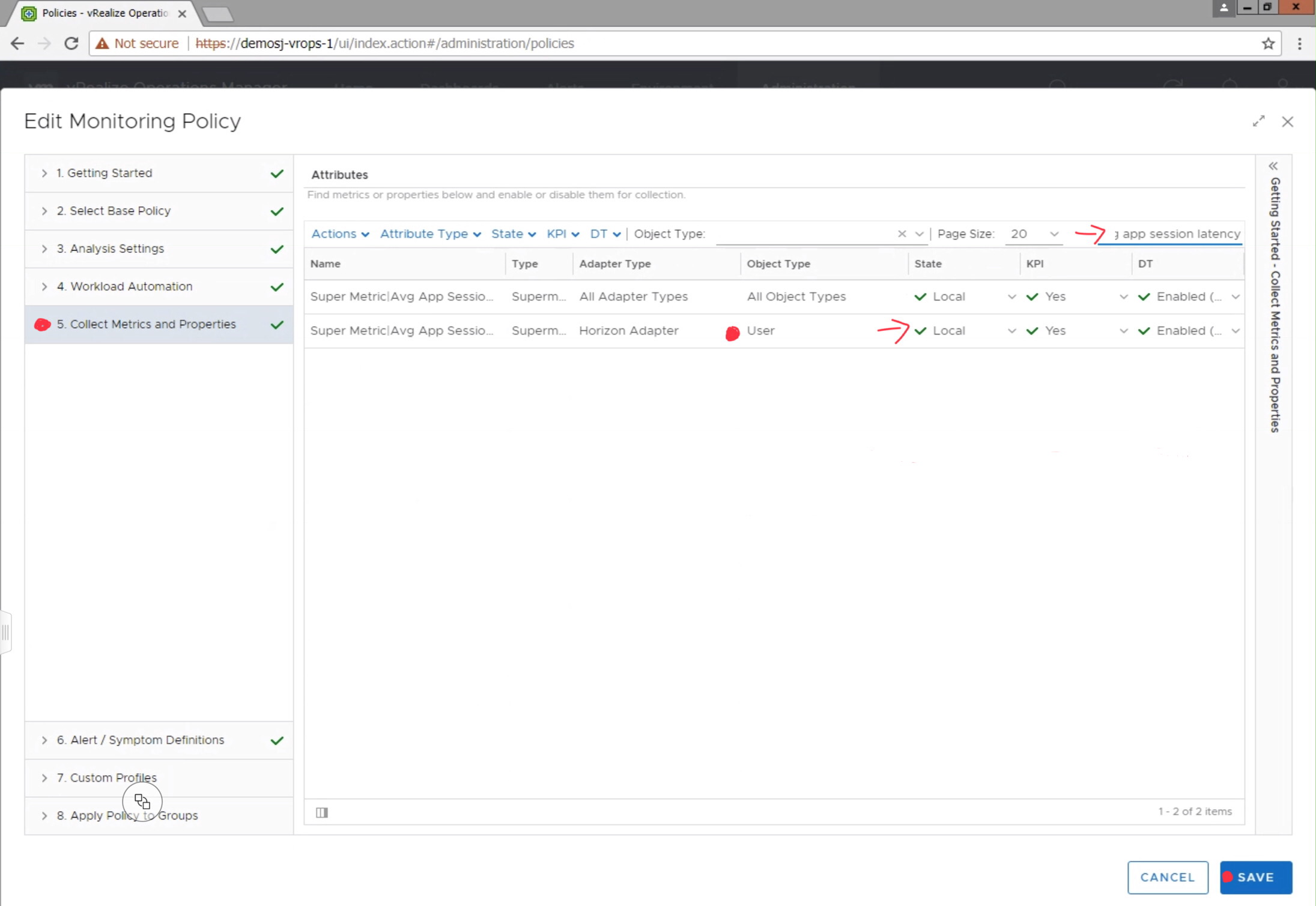
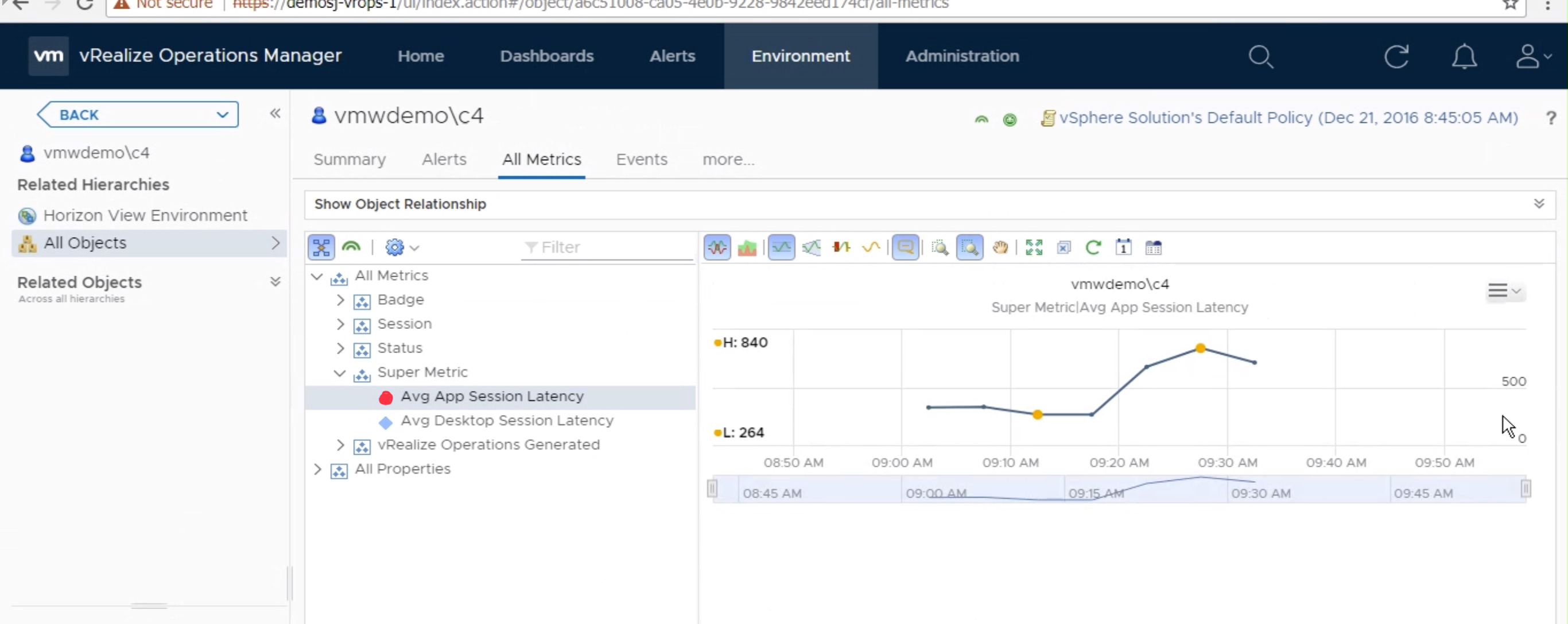
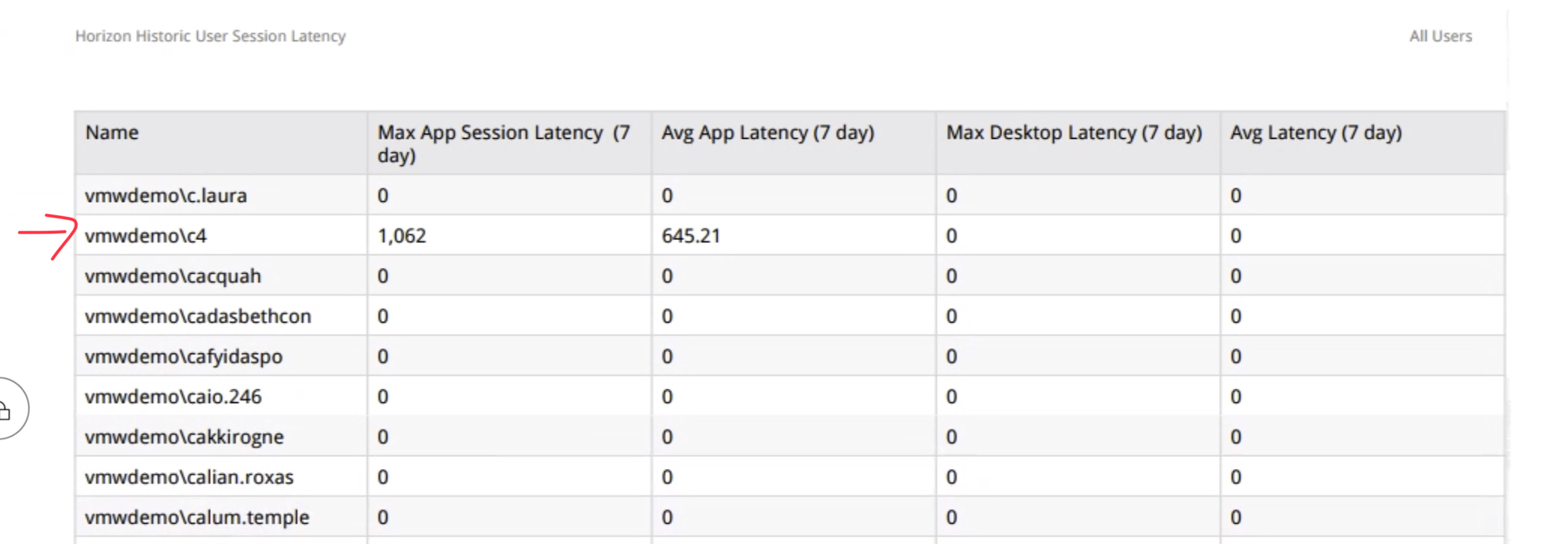
I have just discovered this bug care of the tens of thousands of flapping alerts I’ve received in the last month.
Checking my federated vROps cluster to compile a report on the number of alerts generated over December I was greeted with a significantly higher number than I was expecting, especially considering the Christmas Change Freeze which would stop any non urgent tasks. Further investigation showed that it was due to a few dozen alert definition appearing thousands of times each (>6k alerts for one alert type on one cluster for example)
This appears to affect any alert based on receiving a fault symptom, such as all the default vSAN Management Pack Alerts for example.
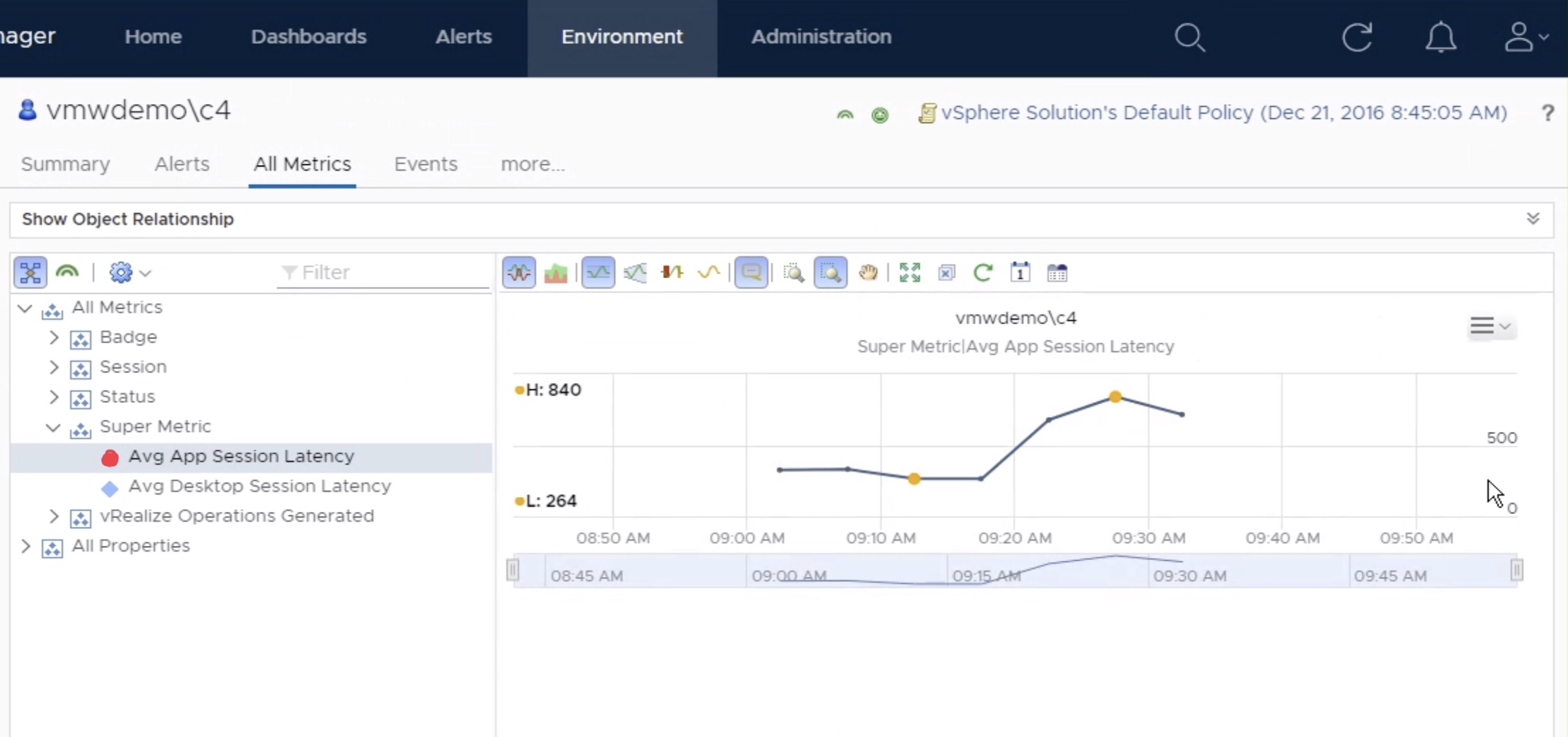
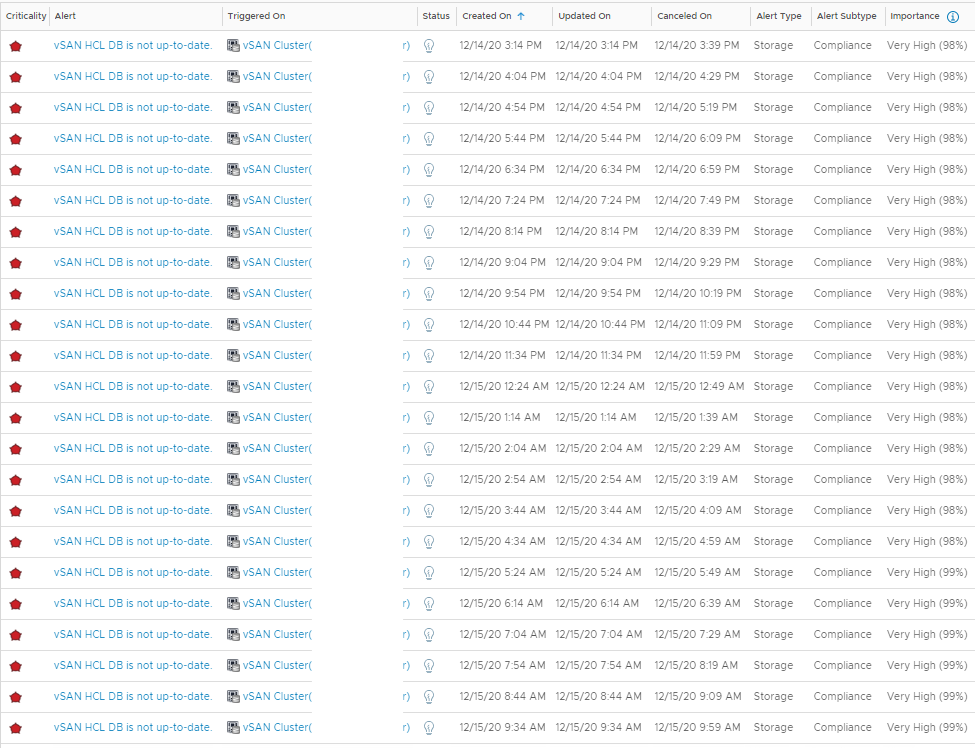
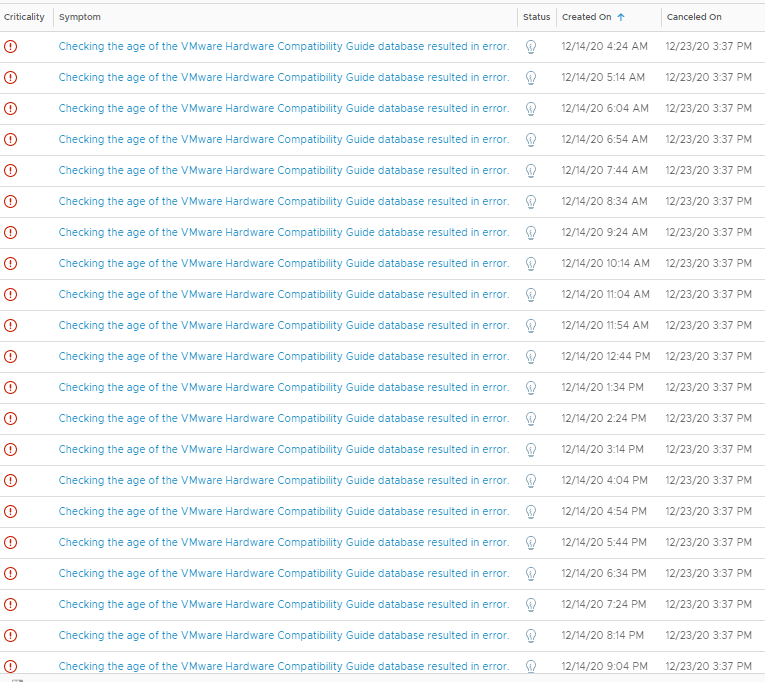
This manifests itself as an alert going active, and then soon after cancelling, and then reactivating aka flapping. See below for an example for one cluster where the HCL DB wasn’t up to date.
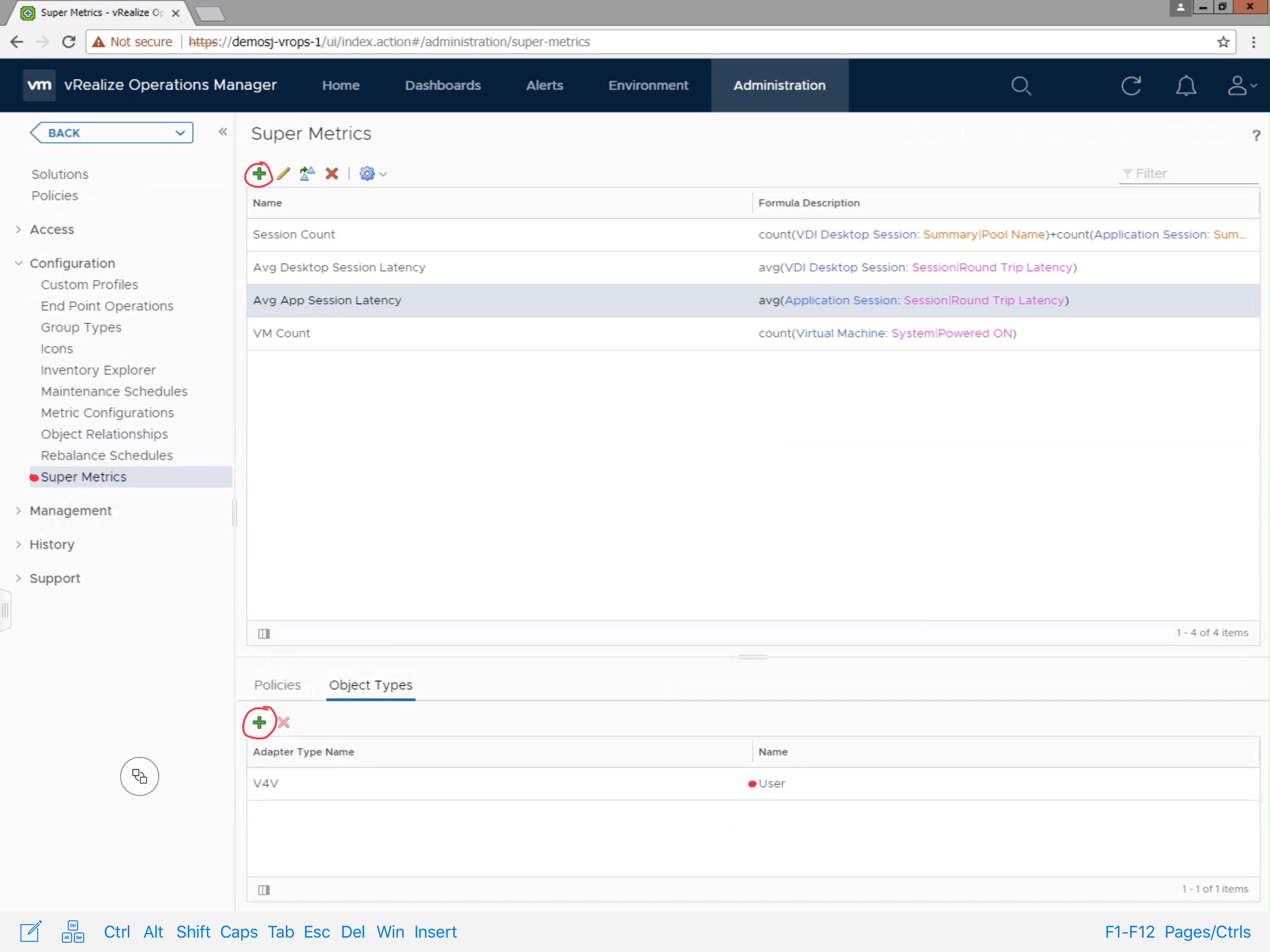
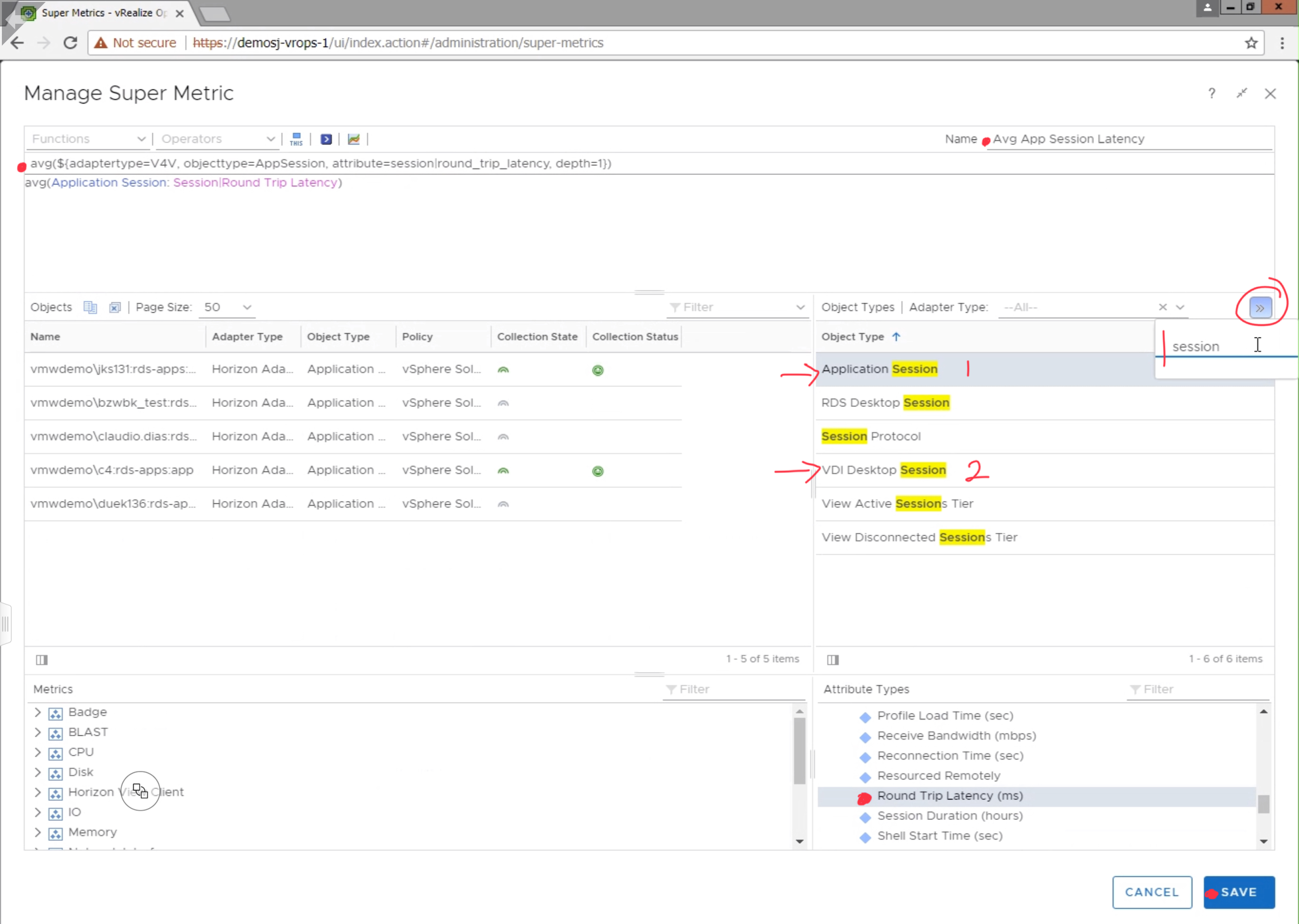
And the cause of this bug is seen in the symptoms view on the object where it creates a new symptom every time instead of updating the existing fault symptom.
If you look at the “cancelled on” value, they were all showing active at the same time, and cancelled when the vSAN HCL DB was updated around 3:30pm on the 23th December. The 50 minute regularity seems to tie in with the vSAN Health Check interval on the vCenter.
I am running vROps 8.1.1 (16522874), but not sure whether this impacts all versions of vROps 8.x but if you see this on any other versions, let me know.
Luckily there is a fix, HF4 which will take you to vROps version 8.1.1 (17258327)
As this pak file is 2.2GB in size, I am unable to host it on my blog for easy download, so I suggest you speak to your VMware TAM, Account Manager, or open a case with Global Support Services and reference this hotfix.
If all else fails I might be able to share it with you using onedrive, however I cannot promise a quick turnaround for that.
UPDATE: I have had it confirmed that this bug affects 8.0 and 8.2 as well, and there are hotfixes for those versions too. The next full release will have the fix built in.
If you are currently on 8.0.x or 8.1.x I would suggest either applying the HF and then upgrading straight to 8.3 when it is released or upgrading to 8.2 first and then applying the HF.